The Evolution of OCR: From Rule-Based to AI-Powered
Explore OCR's evolution from template matching to AI-powered deep learning. Four generations transformed invoice processing accuracy from 70% to 99%.

OCR technology didn't suddenly appear as the sophisticated AI-powered system we use today. It evolved through four distinct generations, each solving fundamental limitations of the previous one. Understanding this evolution explains why modern invoice processing capabilities differ so dramatically from systems built even five years ago.
The journey from rigid template matching to intelligent deep learning represents one of the most dramatic transformations in business automation technology.
First Generation: Template-Based OCR (1970s to 1990s)
The commercial OCR industry began in 1974 when Ray Kurzweil developed the first omni-font OCR system. Unlike earlier devices that could only read specially designed machine-readable fonts, Kurzweil's innovation recognized text in virtually any standard typeface.
Template-based OCR worked through pixel-by-pixel pattern matching. The system stored templates for each character and compared incoming images against those templates. If enough pixels matched the stored pattern for the letter A, the system output an A.
This approach required extremely controlled conditions. Documents needed consistent fonts, uniform spacing, perfect alignment, and high-quality scans. Change the font slightly and accuracy plummeted. Rotate a page two degrees and recognition failed completely.
For invoice processing, template OCR meant creating vendor-specific configurations. Each major supplier required a custom template defining exact field locations. The invoice number always appears 2 inches from the top right. The total sits 6 inches from the bottom. This rigidity achieved high accuracy on known formats but couldn't generalize.
Template-based systems dominated the 1980s and early 1990s, achieving perhaps 70 to 85% accuracy under real-world conditions with mixed document types. The technology worked but required massive configuration effort and constant maintenance as vendor formats changed.
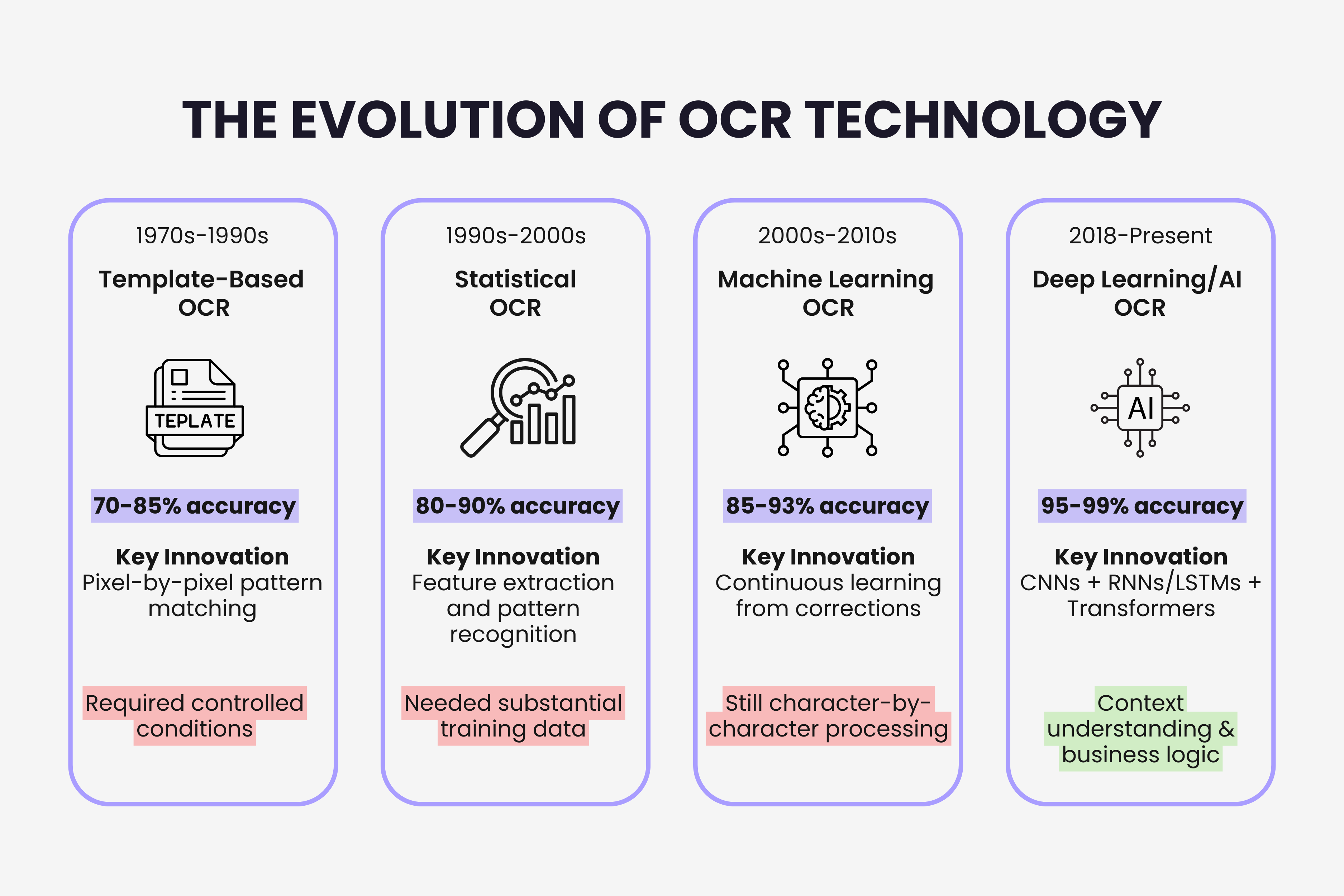
Second Generation: Statistical OCR (1990s to 2000s)
Statistical OCR emerged in the 1990s with a conceptual breakthrough. Instead of rigid pixel matching, statistical models learned patterns from training data using feature extraction and pattern recognition algorithms.
These systems analyzed character features like curves, intersections, line angles, and stroke patterns rather than exact pixel positions. They extracted features from thousands of character examples and built statistical models identifying which feature combinations corresponded to which characters.
This approach handled font variation far better than templates. A statistical model trained primarily on Arial could recognize Times New Roman with reasonable accuracy because it learned underlying character shapes rather than exact pixel arrangements. The system understood that the letter A typically contains two angled lines meeting at a point with a horizontal crossbar, regardless of specific font styling.
For invoice processing, statistical OCR meant businesses could handle documents from multiple vendors without creating individual templates for each. The same system processed invoices in different fonts and layouts by recognizing text patterns statistically rather than matching exact positions.
Statistical OCR pushed accuracy into the 80 to 90% range on variable real-world documents. The technology became commercially viable for businesses receiving invoices from dozens of different suppliers. However, the systems still struggled with poor image quality, unusual layouts, and required substantial training data.
Third Generation: Machine Learning OCR (2000s to 2010s)
Machine learning fundamentally changed OCR in the 2000s by introducing systems that learned continuously from corrections rather than requiring complete retraining.
ML-based OCR used algorithms like Support Vector Machines, k-Nearest Neighbors, and Bayesian classifiers trained on labeled datasets. These systems didn't just recognize patterns from initial training. They adapted as users corrected mistakes during actual operation.
When a finance team member corrected a misread vendor name from "Acc0unting Services" to "Accounting Services", the ML system incorporated that correction. The next invoice from that vendor processed more accurately. Over time, the system specialized to each business's specific vendors and invoice formats.
This continuous improvement changed the value equation completely. Template and statistical systems degraded over time as formats evolved. ML systems improved with use. The longer you operated the system, the better it performed for your specific needs. Learn more about how machine learning improves OCR through continuous training.
ML OCR achieved 85 to 93% accuracy on real-world mixed-format invoices. This accuracy crossed the threshold where automation saved more time than manual correction consumed. Businesses could finally achieve ROI on invoice automation without requiring perfectly standardized input documents.
However, ML OCR still operated primarily on visual pattern recognition. The systems couldn't understand context the way humans do. They learned that certain patterns meant invoice numbers but couldn't infer meaning from surrounding information or apply business logic to extracted data.
Fourth Generation: Deep Learning and AI (2018 to Present)
Modern AI-powered OCR uses deep neural networks that process documents fundamentally differently from previous generations. The breakthrough came in 2018 when Google released Tesseract 4.0, the first major OCR engine incorporating deep learning through LSTM (Long Short-Term Memory) networks.
Deep learning OCR employs Convolutional Neural Networks for image analysis and Recurrent Neural Networks for sequence recognition. These architectures understand document structure, spatial relationships, and contextual meaning rather than just recognizing isolated characters.
A deep learning system analyzing an invoice understands that "Total:" appears near the bottom, that numbers to its right likely represent the total amount, and that this value should match the sum of line items above. The system processes entire documents holistically, applying business logic and contextual understanding alongside character recognition.
Computer vision techniques identify tables, recognize document sections, and understand layout structure before attempting text extraction. This preprocessing is how modern Invoice OCR handles such varied invoice formats successfully.
The newest frontier combines OCR with Transformer-based language models like Microsoft's TrOCR. These systems don't just recognize text visually. They understand what the text means in business context. A transformer model knows that "Net 30" in payment terms means payment due 30 days after invoice date, even encountering that phrasing for the first time.
Transfer learning allows these models to achieve high accuracy with minimal training data. Models pretrained on millions of general documents adapt to specific invoice formats with just dozens of examples. Discover how AI reads invoices using these advanced architectures.
Current deep learning OCR achieves 95 to 99% accuracy on mixed real-world invoices. More importantly, confidence scoring identifies uncertain extractions for human review rather than processing everything blindly. The system knows when it doesn't know, flagging 5% of extractions for verification instead of producing silent errors across 100%.
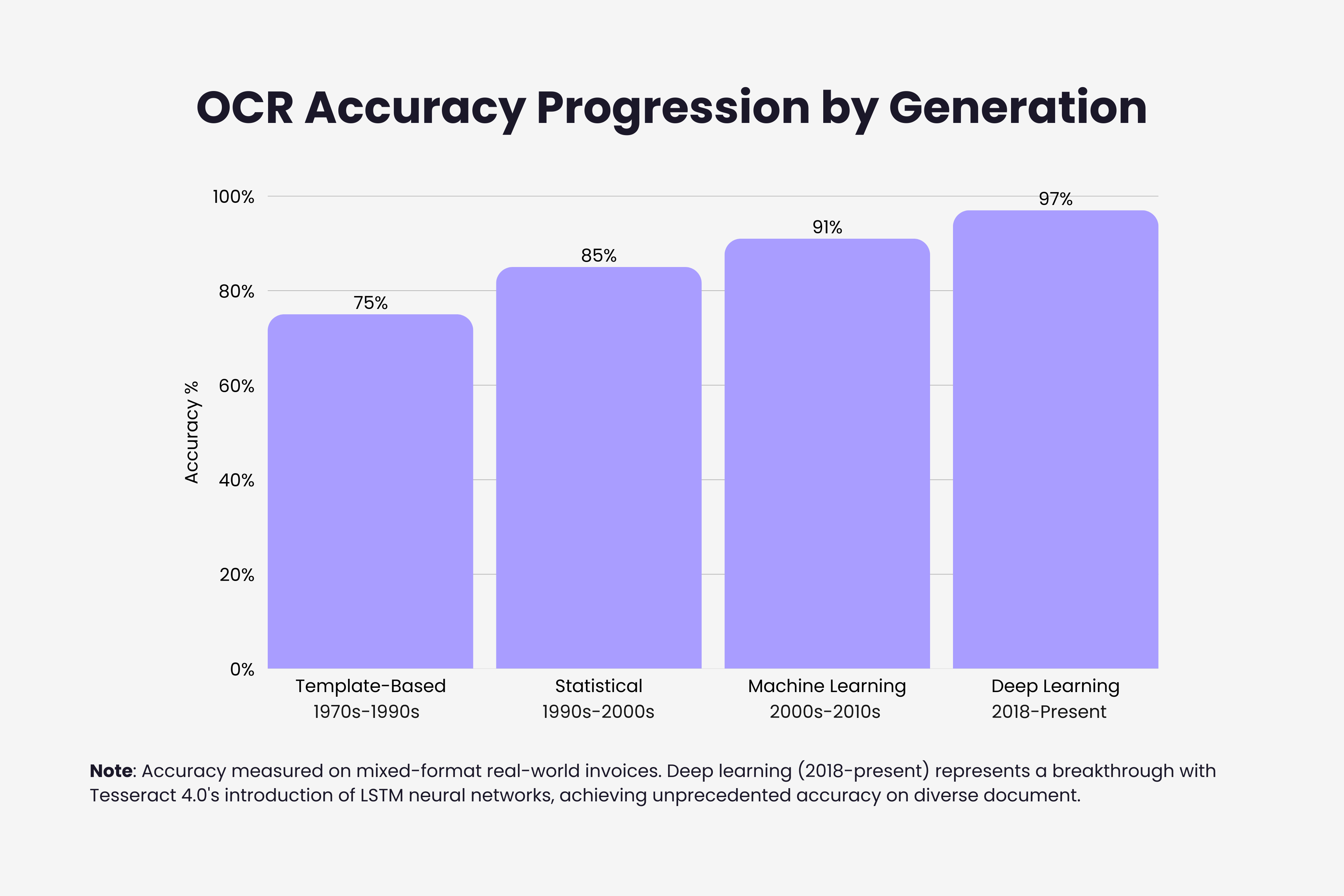
What These Four Generations Mean For Invoice Processing
Each OCR generation solved specific problems that made the previous generation impractical for real-world invoice automation. Template-based systems couldn't handle variation. Statistical models couldn't adapt to specific business needs. Machine learning couldn't understand context. Deep learning addresses all three limitations simultaneously.
The accuracy progression tells part of the story. Moving from 75% (templates) to 88% (statistical) to 91% (ML) to 97% (deep learning) represents dramatic improvement in practical usability. But the conceptual breakthroughs matter more than percentage gains.
Template OCR required businesses to standardize vendor formats. Statistical OCR allowed format variation but required retraining for new document types. Machine learning adapted continuously but still worked character by character. Deep learning understands business context and document meaning, not just visual patterns.
For businesses evaluating invoice automation today, understanding OCR generations explains vendor capabilities better than marketing claims. A solution using 2010-era ML techniques might advertise 90% accuracy, but that's under ideal conditions with clean scans and standard layouts. Real-world performance with your actual mixed-format invoices could be 75 to 80%.
Modern deep learning systems claiming 95% accuracy typically exceed that in practice because they handle variation, poor quality, and complex layouts that break older generations. The architecture differences create practical capability gaps far larger than accuracy percentages suggest.
The evolution continues accelerating. Improvements that took decades in early OCR now happen in months. New neural network architectures emerge regularly, each pushing accuracy and capability boundaries further. The next breakthrough likely involves even tighter integration between vision models and language understanding, moving OCR from data extraction to true document comprehension.
Today's fourth-generation systems represent the backbone of modern AI invoice processing, combining all these evolutionary advances into a single pipeline.
Key Takeaways
OCR technology evolved through four distinct generations over 50 years. Template-based OCR (1970s to 1990s) used pixel matching and required controlled conditions. Statistical OCR (1990s to 2000s) learned patterns from training data and handled font variation. Machine learning OCR (2000s to 2010s) adapted continuously from user corrections. Deep learning OCR (2018 to present) understands document context and business meaning through neural networks.
Accuracy improved from 70 to 85% with templates, to 80 to 90% with statistical methods, to 85 to 93% with machine learning, reaching 95 to 99% with deep learning. Each generation delivered exponentially better performance on real-world mixed-format documents.
The conceptual breakthroughs matter more than incremental accuracy gains. Moving from rigid templates to learned patterns, from static models to continuous adaptation, and from character recognition to contextual understanding fundamentally changed what OCR could accomplish. Modern systems solve problems that previous generations couldn't approach.
Current deep learning OCR handles invoice variations, mixed content, degraded image quality, handwritten notes, complex tables, and multiple languages that would have been impossible for earlier generations. The technology crossed the threshold from assisted data entry to true intelligent automation.
When evaluating invoice OCR solutions, understanding which technology generation powers the system explains expected performance better than vendor marketing. The difference between statistical models from 2005 and deep learning systems from 2023 shows up dramatically in real-world accuracy on your actual invoices. Choose solutions using current-generation deep learning architectures for invoice automation that actually delivers ROI.
Ready to automate your invoices?
Start extracting invoices from your email automatically with Gennai. Free plan available, no credit card required.
Start FreeRelated Articles
ABA Files Made Simple: How to Pay Australian Suppliers in Bulk Without Touching Your Bank
Generate ABA files for batch payments to Australian suppliers directly from your captured invoices. Skip the spreadsheet, skip the manual upload, pay everyone at once. Now live in Gennai.
GuideHow to Capture Invoices via WhatsApp and Telegram: From Photo to Accounting in 30 Seconds
Send a photo of any invoice or receipt to WhatsApp or Telegram and have it captured, extracted, and synced to your accounting tool automatically. The fastest way to digitize paper receipts.
GuideAuto-Categorize Xero Invoices: How AI Learns Your Account Coding from Historical Data
See how Gennai auto-suggests Xero account codes by learning from your invoice history. Cut bill review time, reduce coding errors, and export pre-coded bills straight to Xero.